
انویدیا منتشر کرد: نسخهای از مدل لاما 3.1 که کوچکتر و قویتر از DeepSeek R1 است
این مدل جدید باوجود اندازه کوچکتر عملکردی بهتر از DeepSeek R1 دارد.
در دیجیاتو ثبتنام کنید
جهت بهرهمندی و دسترسی به امکانات ویژه و بخشهای مختلف در دیجیاتو عضو ویژه دیجیاتو شوید.
عضویت در دیجیاتو
متا همچنان درگیر پاسخ به پرسشها و انتقادات درباره خانواده مدلهای جدید Llama 4 است اما شرکت انویدیا با معرفی مدل زبان بزرگ (LLM) متنباز و قدرتمند، توجهها را به خود جلب کرده است. این مدل که Llama-3.1 Nemotron Ultra نام دارد، بر پایه نسخه قبلی مدلهای Llama-3.1-405B-Instruct متا توسعه یافته و به گفته انویدیا، عملکردی نزدیک به برترین مدلهای موجود دارد.
مدل Llama-3.1-Nemotron-Ultra-253B-v1 با 253 میلیارد پارامتر برای وظایفی مانند استدلال پیشرفته، پیروی از دستورات و ایفای نقش دستیار هوش مصنوعی طراحی شده است.
این مدل نخستین بار مارس در کنفرانس سالانه GTC انویدیا معرفی شده بود و اکنون کامل و متنباز در پلتفرم Hugging Face در دسترس قرار گرفته است. کد مدل، وزنها و دادههای پس از آموزش آن نیز عمومی منتشر شدهاند.

مدل جدید انویدیا با استفاده از فرایند جستجوی معماری عصبی (NAS) توسعه یافته که در آن نوآوریهایی مانند حذف لایههای توجه، شبکههای Fused feedforward و فشردهسازی متغیر در ساختار مدل اعمال شدهاند. این معماری به گونهای طراحی شده که مدل با کاهش مصرف حافظه و منابع محاسباتی، همچنان کیفیت خروجی بالایی ارائه دهد و بتوان آن را فقط با 8 کارت گرافیک H100 اجرا کرد.
علاوهبر H100، این مدل با معماریهای پیشرفتهتر انویدیا مانند B100 و Hopper نیز سازگار بوده و در حالتهای دقت BF16 و FP8 عملکرد مطلوبی دارد.
انویدیا برای ارتقای تواناییهای مدل از فرایند پسآموزش چندمرحلهای بهره برده که شامل آموزش نظارتشده در حوزههایی مانند ریاضی، تولید کد، چت و استفاده از ابزارها بوده است. همچنین برای بهبود عملکرد در دنبالکردن دستورات و توانایی استدلال، از الگوریتم GRPO (بهینهسازی نسبی سیاست گروهی) استفاده شده است.
عملکرد مدل جدید انویدیا در برابر رقبا
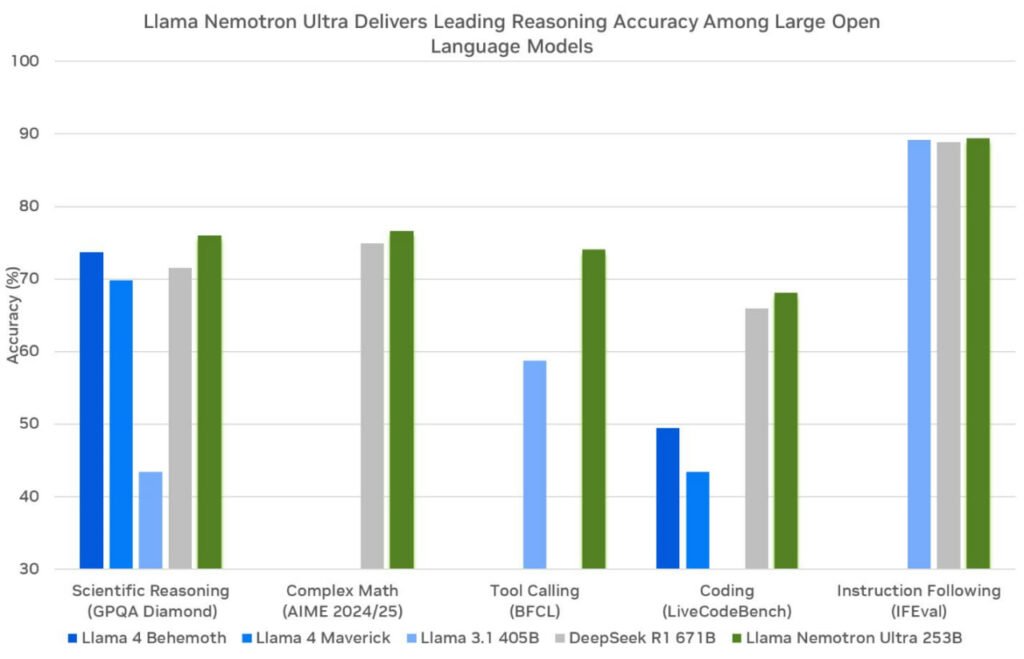
مدل جدید انویدیا در آزمونهای معتبر مختلف عملکرد خیرهکنندهای داسته است. برای مثال، در آزمون MATH500، عملکرد مدل از 80.40 درصد در حالت عادی به 97 درصد در حالت استدلال افزایش یافته است. همچنین در آزمون AIME25، امتیاز آن از 16.67 درصد به 72.50 درصد و در LiveCodeBench از 29.03 درصد به 66.31 درصد رسیده است.
این مدل در پاسخ به پرسشهای عمومی (GPQA) در حالت استدلال فعال به امتیاز 76.01 درصد دست یافته که از DeepSeek R1 (با امتیاز 71.5 درصد) پیشی گرفته است. همچنین در آزمون IFEval برای پیروی از دستورات، امتیاز 89.45 درصد در برابر 83.3 درصد رقیب ثبت شده و در LiveCodeBench نیز اندکی بهتر عمل کرده است.
البته باید توجه کرد که مدل DeepSeek R1 در برخی آزمونهای ریاضی سنگین همچنان بهتر عمل میکند، ازجمله در AIME25 با امتیاز 79.8 درصد برابر 72.50 درصد مدل انویدیا.
این مدل از زبانهای متعددی ازجمله انگلیسی، آلمانی، فرانسوی، ایتالیایی، پرتغالی، هندی، اسپانیایی و تایلندی پشتیبانی میکند و برای کاربردهایی مانند چتبات، ساخت عاملهای هوش مصنوعی، تولید کد و تولید با روش بازیابی-افزوده (RAG) قابلاستفاده است.








برای گفتگو با کاربران ثبت نام کنید یا وارد حساب کاربری خود شوید.