
تحقیق اپل: مدلهای زبانی میتوانند با دادههای صوتی و حرکتی تشخیص دهند چه کار میکنید
مدلهای LLM با دادههای صوتی و حرکتی میتوانند تحلیل بهتری از فعالیتهای کاربر داشته باشند.
در دیجیاتو ثبتنام کنید
جهت بهرهمندی و دسترسی به امکانات ویژه و بخشهای مختلف در دیجیاتو عضو ویژه دیجیاتو شوید.
عضویت در دیجیاتو
اپل تحقیق جدیدی منتشر کرده که نشان میدهد مدلهای زبانی بزرگ (LLM) چگونه میتوانند دادههای صوتی و حرکتی را تحلیل کنند تا دید بهتری از فعالیتهای کاربر به دست آورند.
یک مقاله جدید با عنوان «استفاده از LLMها برای ادغام چند حسی سنسورها در تشخیص فعالیت» اطلاعاتی درباره اینکه اپل چگونه ممکن است از تحلیل LLM در کنار دادههای سنتی سنسورها برای درک دقیقتر فعالیت کاربر استفاده کند، ارائه میدهد. به گفته محققان، این روش پتانسیل بالایی برای افزایش دقت تحلیل فعالیتها حتی در شرایطی که دادههای کافی از سنسور موجود نیست، دارد.
مدلهای زبانی بزرگ میتوانند با دادههای کمتر نوع فعالیت کاربر را مشخص کنند
در این تحقیق مشخص شد که مدلهای زبانی بزرگ توانایی بسیار قابلتوجهی در استنباط فعالیتهای کاربر از طریق سیگنالهای صوتی و حرکتی دارند، حتی اگر بهصورت خاص برای این کار آموزش ندیده باشند. همچنین وقتی تنها یک مثال به آنها داده میشود، دقتشان حتی بیشتر هم میشود.
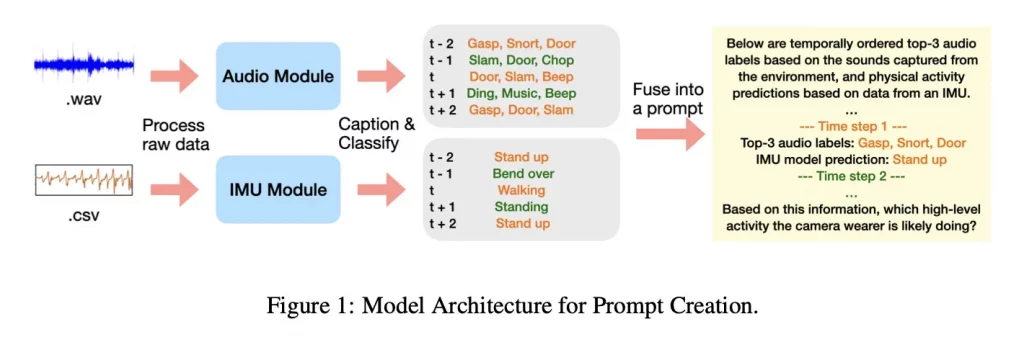
یک تفاوت مهم این است که در این مطالعه، LLM خود فایل صوتی واقعی را دریافت نکرده بود، بلکه توضیحات کوتاه متنی تولیدشده توسط مدلهای صوتی و یک مدل حرکتی مبتنی بر IMU به آن داده شد. IMU یا دستگاه سنجش لختی (اینرسی) حرکت را از طریق دادههای شتابسنج و ژیروسکوپ دنبال میکند.
در این مقاله، محققان توضیح دادهاند که از Ego4D (یک مجموعه داده عظیم از رسانههایی که با دیدگاه اولشخص ضبط شده) استفاده کردهاند. این دادهها شامل هزاران ساعت اطلاعات از محیطها و موقعیتهای واقعی از کارهای خانه گرفته تا فعالیتهای فضای باز هستند.
محققان دادههای صوتی و حرکتی را از طریق مدلهای کوچکتر عبور دادند که زیرنویس متنی و پیشبینی کلاسها را تولید میکردند، سپس این خروجیها را به مدلهای مختلف LLM مانند جمینای ۲.۵ پرو و Qwen-32B دادند تا ببینند چقدر میتوانند فعالیتها را شناسایی کنند.

اپل عملکرد این مدلها را در دو وضعیت مختلف مقایسه کرد؛ یکی زمانی که لیست ۱۲ فعالیت ممکن برای انتخاب در اختیارشان قرار گرفت و دیگری زمانی که هیچ گزینهای داده نشد.
محققان در پایان اشاره میکنند که نتایج این مطالعه اطلاعات جالبی درباره نحوه ترکیب چند مدل برای تحلیل دادههای فعالیت و سلامت ارائه میدهد، بهویژه در مواردی که دادههای خام سنسورها به تنهایی کافی نیستند تا تصویر واضحی از فعالیت کاربر ارائه دهند.













برای گفتگو با کاربران ثبت نام کنید یا وارد حساب کاربری خود شوید.