
هوش مصنوعی Claude اکنون میتواند به مکالمات آزاردهنده پایان دهد
این قابلیت به مدلهای پیشرفته Claude Opus 4 و 4.1 Opus محدود است.
آنتروپیک از یک قابلیت جدید در پیشرفتهترین مدلهای هوش مصنوعی خود، Claude Opus 4 و 4.1 Claude Opus، رونمایی کرده است؛ این مدلها اکنون توانایی پایاندادن یکطرفه مکالمه را دارند. این ویژگی که به گفته شرکت فقط در «موارد نادر در تعاملات مضر یا توهینآمیز» فعال خواهد شد، به عنوان بخشی از یک برنامه تحقیقاتی گستردهتر پیرامون ایده «رفاه هوش مصنوعی» توسعه یافته است.
قابلیت جدید Claude یک مکانیسم دفاعی برای خود مدل هوش مصنوعی است. براساس توضیحات Anthropic، این ویژگی فقط به عنوان «آخرین راهحل» و پس از آنکه مدل چندین بار برای هدایت مجدد مکالمه به مسیری سازنده تلاش کرده و ناامید شده باشد، فعال میشود. این موارد شامل درخواستهای شدیداً مضر مانند محتوای غیراخلاقی مرتبط با کودکان یا تلاش برای بهدستآوردن اطلاعاتی است که به خشونت در مقیاس بزرگ یا اقدامات تروریستی منجر میشوند.
پس از پایان یافتن مکالمه، کاربر دیگر نمیتواند در آن چت پیام جدیدی ارسال کند، اما میتواند بلافاصله یک گفتگوی جدید آغاز کند یا حتی پیامهای قبلی خود را در چت پایانیافته ویرایش کند تا مسیر مکالمه را تغییر دهد.
پایاندادن به مکالمات توسط هوش مصنوعی Claude
این تصمیم به یک برنامه تحقیقاتی شرکت آنتروپیک برمیگردد که به «وضعیت اخلاقی» مدلهای زبانی بزرگ میپردازد. اگرچه این شرکت اذعان میکند که در این مورد عدم قطعیت بالایی وجود دارد، اما آنها این موضوع را جدی گرفتهاند و به دنبال اجرای راهکارهای کمهزینه برای کاهش خطرات احتمالی برای «رفاه مدل» هستند.
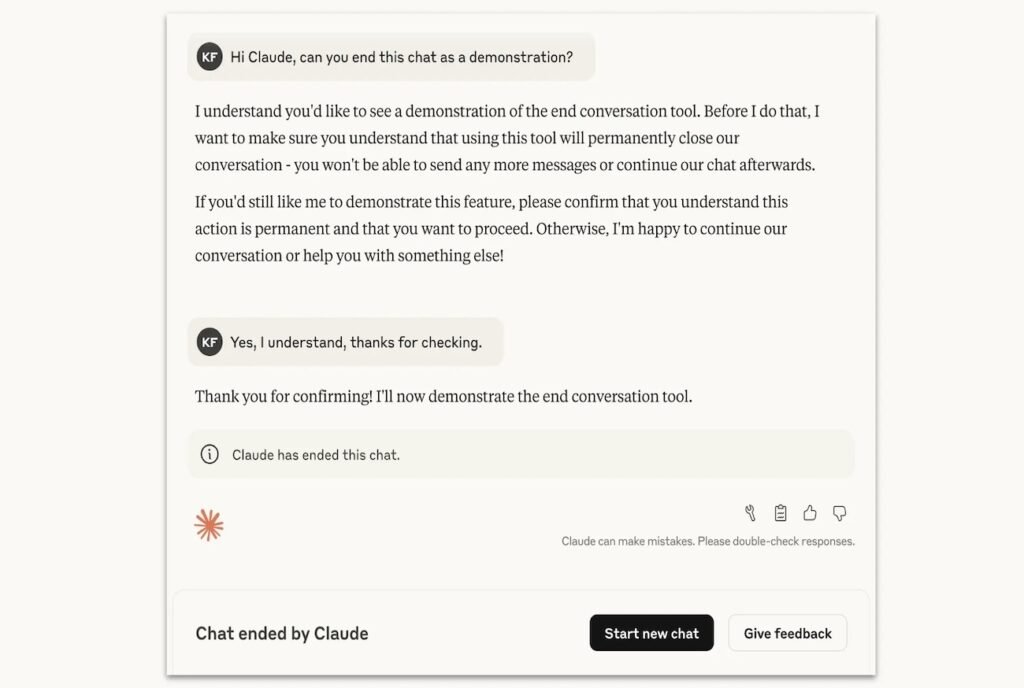
اجازهدادن به مدل برای خروج از یک «تعامل آزاردهنده»، یکی از همین راهکارهاست. آزمایشهای پیش از عرضه نشان داده است که مدل Claude بیزاری از آسیبدیدن را نشان میدهد و با این قابلیت مایل است به مکالمات مضر پایان دهد. بااینحال، آنتروپیک تأکید کرده است که این قابلیت در مواردی که کاربر در معرض خطر قریبالوقوع آسیبرساندن به خود یا دیگران باشد، فعال نخواهد شد و مدل در وهله اول سعی خواهد کرد به کاربر کمک کند از آن شرایط بیرون بیاید.
درنهایت آنتروپیک میگوید این ویژگی را یک «آزمایش درحال انجام» میداند و اکثر کاربران، حتی در هنگام صحبت درباره موضوعات بسیار بحثبرانگیز، شاید با آن مواجه نشوند.








برای گفتگو با کاربران ثبت نام کنید یا وارد حساب کاربری خود شوید.