
مدل جدید Stable Audio 3.0 معرفی شد؛ ساخت آهنگهای ۶ دقیقهای با هوش مصنوعی
Stable Audio 3.0 شامل 4 نسخه در اندازههای مختلف میشود. مدلهای کوچکتر بهصورت متنباز و مدل بزرگتر از طریق API قابل دسترس است.
در دیجیاتو ثبتنام کنید
جهت بهرهمندی و دسترسی به امکانات ویژه و بخشهای مختلف در دیجیاتو عضو ویژه دیجیاتو شوید.
عضویت در دیجیاتوتازههای تکنولوژی




شرکت Stability AI، سازنده مدل معروف Stable Diffusion، نسل جدیدی از مدلهای صوتی خود را با نام Stable Audio 3.0 معرفی کرد. این خانواده جدید از مدلهای هوش مصنوعی، آهنگهای باکیفیت با حداکثر زمان ۶ دقیقه و ۲۰ ثانیه تولید کند.
مدلهای Stable Audio 3.0
خانواده Stable Audio 3.0 شامل چهار مدل مختلف است؛ مدلهای کوچک و مخصوص جلوههای صوتی (SFX) که هرکدام ۴۵۹ میلیون پارامتر دارند، مدل متوسط با ۱.۴ میلیارد پارامتر و مدل بزرگ با ۲.۷ میلیارد پارامتر. طبق اعلام این شرکت، مدلهای کوچک برای تولید صدا و موسیقی روی دستگاه تا سقف ۲ دقیقه بهینه شدهاند.
دو مدل متوسط و بزرگ این خانواده میتوانند قطعات موسیقی کاملی تولید کنند که ساختار موسیقایی و لحن ملودیک خود را در طول بیش از ۶ دقیقه حفظ میکنند. این دستاورد، پیشرفتی بزرگ نسبت به نسخه Stable Audio 2.0 محسوب میشود که سال گذشته عرضه شد و آهنگهای به مراتب کوتاهتری تولید میکرد.
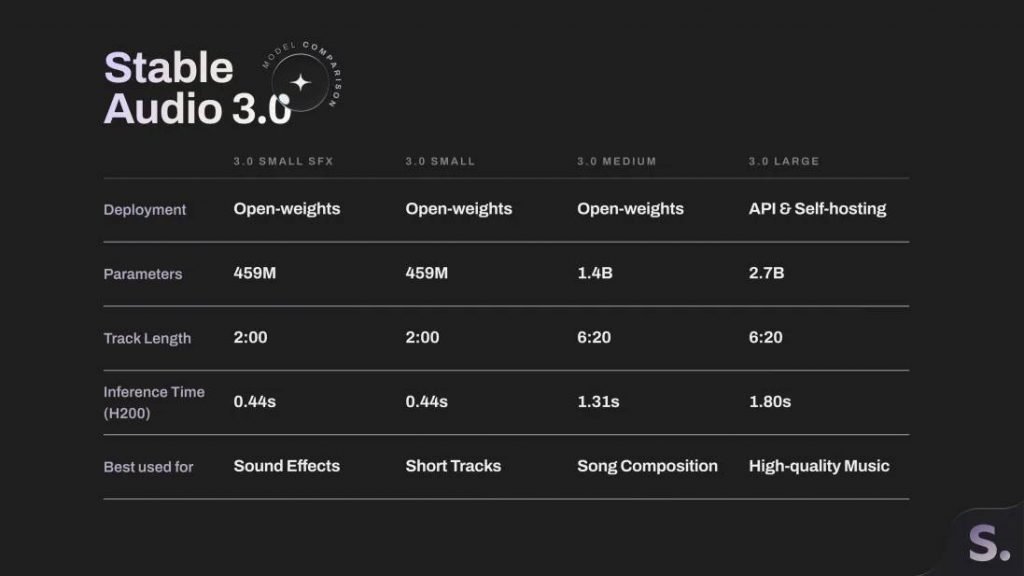
Stability AI اعلام کرده که مدلهای کوچک و متوسط را بهصورت متنباز منتشر میکند تا کاربران بتوانند از آنها استفاده یا تغییراتی در آنها ایجاد کنند. در مقابل، مدل بزرگ تنها از طریق API و سرویسهای میزبانی ابری پولی در دسترس خواهد بود. همچنین شرکتهایی با درآمد سالانه بیش از یک میلیون دلار، برای استفاده از این فناوری ملزم به دریافت مجوز سازمانی هستند.
با توجه به چالشهای حقوقی شرکتهایی نظیر Suno و Udio در زمینه حق کپیرایت، Stability AI تأکید کرده است که مدلهای جدید خود را بر پایه دادههایی با مجوز کامل آموزش داده است. این شرکت سال گذشته قراردادهایی را با غولهای موسیقی جهان یعنی Warner Music Group و Universal Music Group امضا کرده بود.

همچنین، این استارتاپ قصد دارد محصولات ویژهای برای موزیسینهای حرفهای توسعه دهد. در همین راستا، «ایتن کپلن»، مدیر ارشد دیجیتال سابق در شرکتهای Universal Audio و Fender، به تیم Stability پیوسته است تا هدایت بخش موسیقی حرفهای این شرکت را برعهده بگیرد.


دیدگاهها و نظرات خود را بنویسید
برای گفتگو با کاربران ثبت نام کنید یا وارد حساب کاربری خود شوید.







برای همه اعضای دیجیاتو 😘❤️❤️❤️❤️❤️
my playlist is AI mostly 😂
کاش می گفتید کدوم نوع پنلش پولی یه و کدام دسترسی هاس و نرخش چقدره
سلام، در بیانیه رسمی Stability AI فقط توضیح داده شده که سه مدل Small SFX ،Small و Medium بهصورت متنباز و رایگان منتشر شدن و حتی برای استفاده تجاری هم تحت Community License قابل استفادهاند. فقط شرکتهایی با درآمد بالای ۱ میلیون دلار نیاز به لایسنس سازمانی دارند. مدل بزرگتر که بهش Large میگن هم تنها از طریق API پولی یا سرویسهای Enterprise ارائه میشه. Stability قیمت API و لایسنس رو دقیقاً اعلام نکرده.
ممنون ! 😓😅😅😅
چه عجب بلاخره یک مدل موزیک دیفیوزر اومد ، اگه مثل مدل های قبلی Wan و flux انکودر umt5xl استفاده کرده باشند فعلا آهنگ سازان در امان هستند وای از اون روزی که یک شرکت چینی مثل علی بابا بیاد مثل z-image از یک LLM Qwen3 5b استفاده کنه دیگه خودتون تعطیل کنید برید
چرا تعطیل کنن توسعه پذیری بهتر میشه
جدی خیلی رو مخه که هوش مصنوعی رو با هنر ترکیب می کنن هنر باید دست نخورده بمونه باید طبیعی و انسانی باشه نمیگم نباید با تکنولوژی ترکیب بشه ولی یه حدی جدا باید در نظر بگیرن
هوش مصنوعی ابزاری جدید و داره راه خودش باز میکنه.
دفعه قبل با ظهور دوربین های عکاسی دقیقا چنین مخالفتهایی بود. ولی دیدیم که نقاشی برای زنده موندن سبک رئالیسم سپرد به دوربینها و خودش به سبک های مدرن و انتزاعی رو آورد.
دهه ۳۰ میلادی عصر تحول در هنر، تجارت، صنعت و نظام اجتماعی خواهد بود.
نمی گم بده ولی چون طبیعی نیست مخالفشم هنر باید یچیز طبیعی باشه این مصنوعیه خالصه از بابت این که هنر مال موجودات زنده است نظرم اینه که خوب نیست هوش مصنوعی واردش شه
با حرف شما مخالف نیستم و منم به همین معتقدم. کل اینترنت داره با محتواهای به شدت اشغال تماما aI پر میشه. اصلا حالم به هم میزدن(الان که سه ماه واسه همونا هم دلمون تنگ شده)
ولی در کل برعکس شما من از ai استقبال میکنم. معتقدم الان اول راهش و هنوز مسیرش پیدا نکرده. امیدوارم در آینده تبدیل به یه هنر جدید بشه نه این اشغال ها.